1. AI, 단순했던 첫 시작
지란지교시큐리티에서는 AI를 활용해 업무 효율을 높이는 것을 적극 권장하고 있습니다.
하지만 QA(Quality Assurance, 품질보증) 업무를 담당하는 입장에서 이미 수행 중인 업무만으로도 바쁜 상황이었고, AI를 어떻게 접목해야 할지 당장 아이디어를 떠올리기 어려웠습니다. 당시엔 새로운 기술을 따로 공부할 심리적 여유도 없었습니다. 솔직히 개발자도 아닌 제가 어디서부터 시작해야 할지도 감이 잡히지 않았습니다. 그렇게 막막함 속에서 고민하던 중 생각을 바꿔봤습니다.
“그래, 내가 공부하지 말고 AI에게 물어보자.”
부담을 내려놓고, 가장 단순한 방식으로 AI를 시작해 보기로 했습니다.
2. AI 전문 용어부터 파악하기
AI에게 무작정 물어보는 것만으로는 한계가 있었습니다. 질문을 제대로 하려면, 최소한의 개념은 이해해야 했습니다. 그래서 가장 먼저 한 일은 AI와 대화하기 위한 기본 용어를 정리하는 것이었습니다.
■ LangChain
LLM을 단순한 질문-답변 도구가 아니라 업무 흐름 속에서 여러 작업을 연결하는 구조입니다.
데이터 조회 → 정리 → LLM 전달 → 결과 가공 이 과정을 하나의 체인으로 묶어 자동화할 수 있습니다. 처음에는 어렵게 느껴졌지만 결국은 작업을 순서대로 연결하는 방식으로 이해했습니다.
■ Gemma 4 (로컬 LLM)
외부 API가 아닌 내 환경에서 직접 실행하는 AI 모델입니다.
• 데이터 외부 유출 없음
• 자유로운 커스터마이징
• 추가 비용 없음
성능은 일부 상용 모델보다 제한적이지만 업무 자동화에는 충분히 활용 가능했습니다.
■ Vector DB & ChromaDB
기존 DB가 “정확한 값”을 찾는다면 Vector DB는 의미가 비슷한 데이터를 찾습니다. 문장을 벡터로 변환하고 유사도를 기준으로 데이터를 검색합니다. ChromaDB는 로컬 환경에서 쉽게 구축 가능한 Vector DB로 필요한 정보를 빠르게 찾아 LLM에 전달하는 역할을 합니다.
■ 데이터 온톨로지
데이터를 단순히 저장하는 것이 아니라 구조와 관계를 정의하는 것입니다. 어떤 데이터가 있고, 서로 어떻게 연결되어 있으며, 어떤 의미를 가지는지를 명확히 해야 LLM이 데이터를 더 정확하게 이해하고 활용할 수 있습니다.
■ RAG (Retrieval-Augmented Generation)
LLM이 모든 정보를 기억하도록 하는 대신 필요한 순간에 필요한 데이터를 찾아서 답변하는 방식입니다.
- 질문 발생
- 관련 데이터 검색
- 해당 데이터를 기반으로 답변 생성
이 구조를 통해 정확도를 높이고 불필요한 추측을 줄일 수 있었습니다.
AI를 잘 활용하기 위해 중요한 것은 기술 자체가 아니라 개념을 업무에 맞게 이해하는 것이었습니다.
3. AI에게 나를 설명하기
AI를 제대로 활용하려면 먼저 “나에게 맞는 답”을 받을 수 있어야 했습니다. 그래서 가장 먼저 한 일은 AI에게 저를 설명하는 것이었습니다.
- 현재 수행 업무
- 기술 수준 (비개발자)
- 사용하는 시스템
이 정보를 기반으로 제게 필요한 프로그램이 무엇인지 도출했습니다.


4. AI와 목표 정하기
처음부터 단순한 호기심이 아닌 실제로 업무에 사용할 수 있는 시스템 구축을 목표로 했습니다.
그렇게 업무에 접목한 ‘AI 기반 보안 취약점 자동화 플랫폼’ 만들기가 시작되었습니다.
[목표 시스템]
목표 1) 보안 자동화
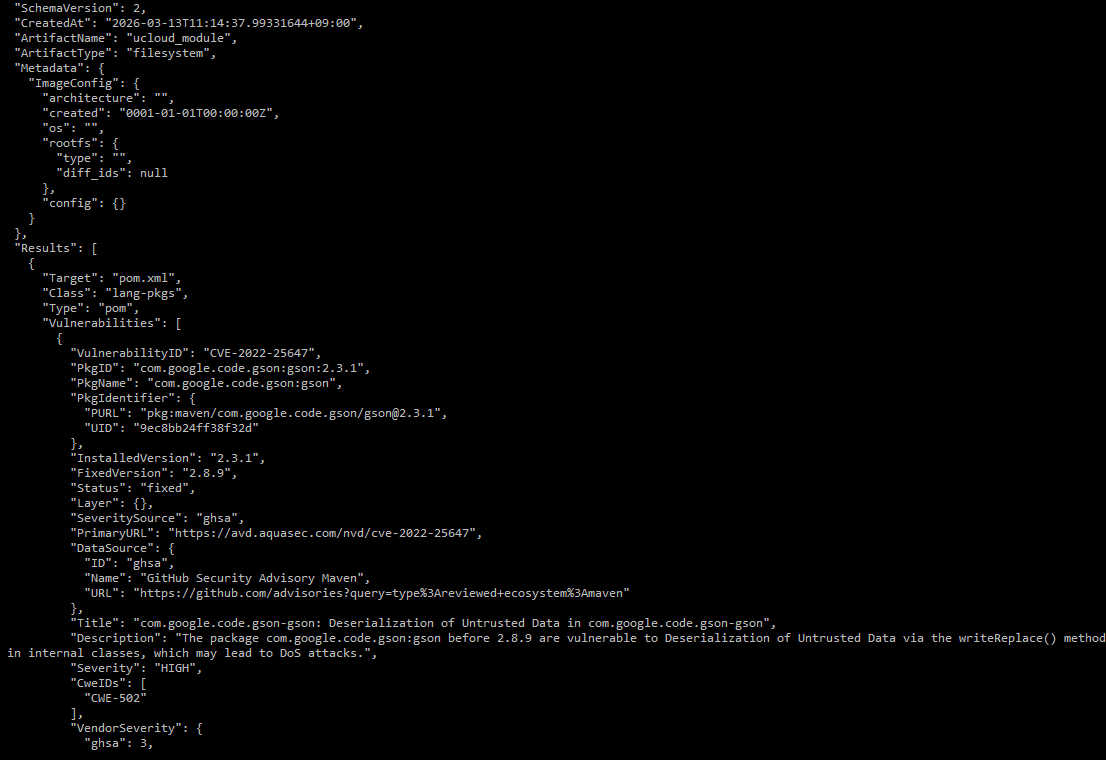
- Trivy 소스코드 보안 스캔 결과 분석
- LLM 기반 분석 및 리포트 재작성
- Jira 티켓 자동 생성 및 관리
목표 2) 지능형 질의 시스템
- Jira / Confluence / Sparrow 데이터 실시간 조회
- 로컬 LLM 기반 응답 생성
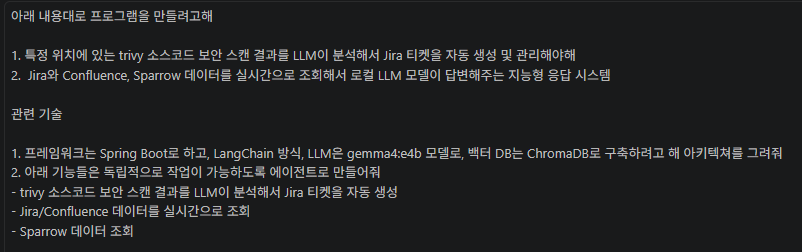
5. 아키텍처 설계하기
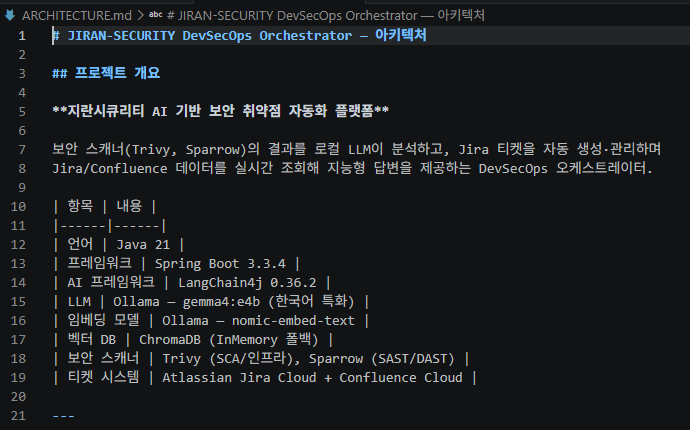
| 기술 스택
- Backend: Spring Boot
빠른 구현이 목표라서 복잡한 설정 없이도 즉시 실행 가능한 '내장 서버'와 필요한 기능 간편 설정이 가능해서 사용했습니다. - LLM 구조: LangChain 방식
멀티 Agent 흐름 제어에 적합하다고 생각되어, LangGraph가 아닌 LangChain을 선택했습니다. - Model: Gemma 4:E4B (Local LLM)
보안 환경에서 서버 사양에 맞는 비교적 가벼운 모델이라 생각해서 선택했습니다. - Vector DB: ChromaDB
서버 환경에서 빠른 구축에 적합할 것이라고 판단해서 선택했습니다.
| AI 분석 (로컬 LLM)
Trivy와 같은 도구로 탐지한 CVE 취약점 스캔 결과를 Ollama 기반 gemma 모델이 분석해서
무엇이 문제인지, 어떻게 조치해야 하는지 판단 후 리포트를 재작성합니다.
| 자동 티켓 생성 & 관리
분석 결과를 바탕으로 Jira에 이슈를 자동 생성하고 관리합니다.
| 지식 연동
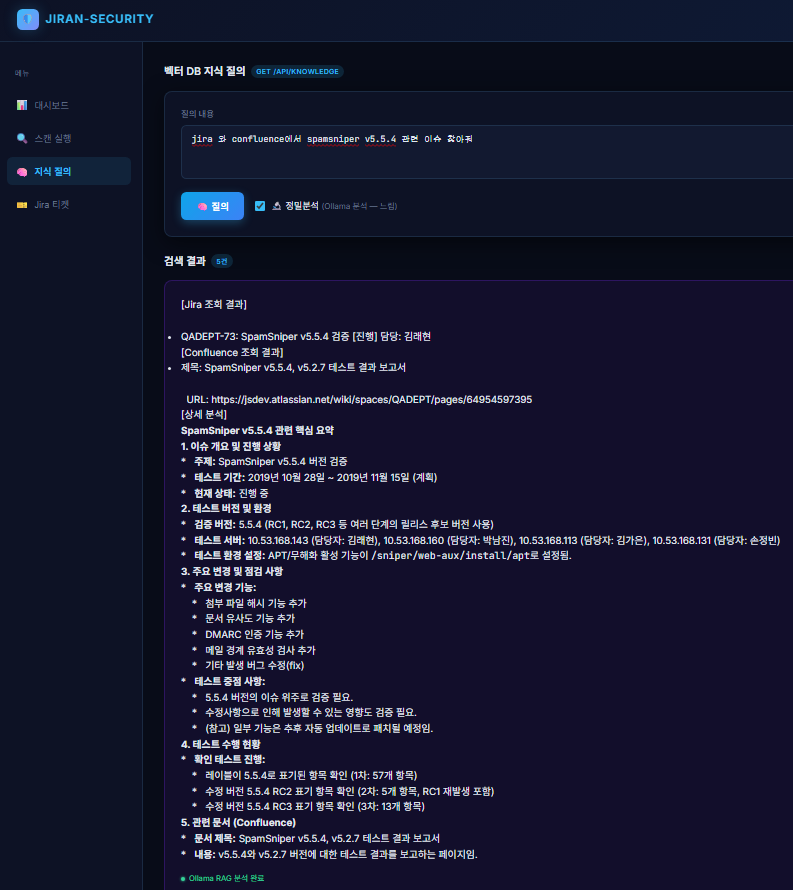
Confluence나 기존 Jira 데이터를 실시간 조회해서 유사 사례, 해결 방법 등을 참고한 “지능형 답변”을 제공합니다.
| 전체 구조
각 Agent는 독립적으로 동작하며 Orchestrator가 전체 흐름을 제어합니다.
[사용자]
↓
[Spring Boot API]
↓
[Agent Orchestrator]
├── Trivy Agent
├── Jira/Confluence Agent
├── Sparrow Agent
↓
[ChromaDB]
↓
[Local LLM]
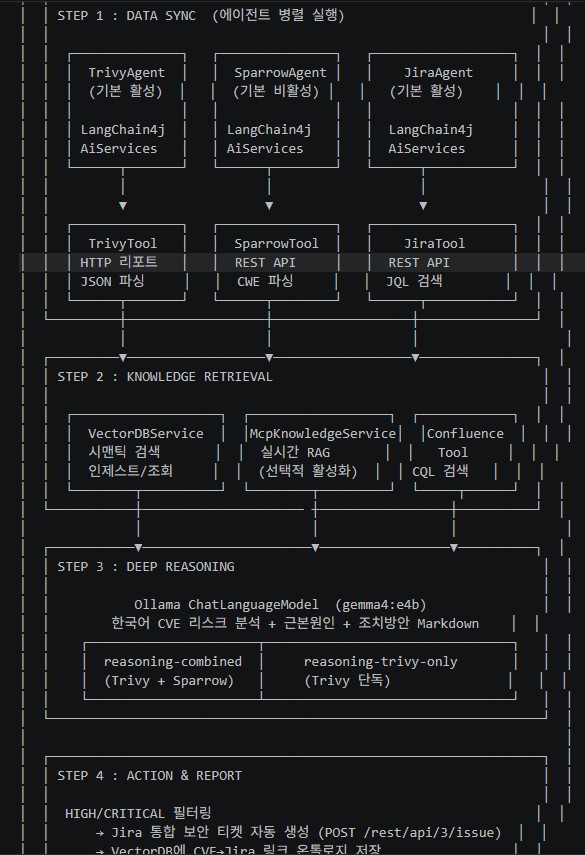
STEP 1: DATA SYNC (에이전트 병렬 실행)
에이전트를 병렬로 실행합니다.
- TrivyAgent (활성)
- 취약점 스캔 결과 수집
- HTTP 리포트 → JSON 파싱 - SparrowAgent (비활성 옵션)
- SAST/DAST 결과 수집
- REST API → CWE 정보 파싱 - JiraAgent (활성)
- 기존 보안 이슈 조회
- JQL로 티켓 검색
STEP 2: KNOWLEDGE RETRIEVAL
수집한 데이터를 “맥락 있는 정보”로 바꾸는 단계입니다.
- VectorDBService
- 임베딩 기반 유사도 검색
- 사내 중요 취약점 분석 데이터 보관
- 스캔 된 데이터 기반으로 과거 사례/유사 취약점 찾기 - MCP Knowledge
- 실시간 RAG (외부/추가 지식)을 CVE 취약점 분석에 사용 - Confluence Tool
- 사내 문서 검색 (CQL)
STEP 3: DEEP REASONING
AI가 추론을 하는 단계입니다.
- Ollama (gemma4:4b) 로컬 LLM이 수행
- 하는 일:
- CVE 위험도 분석
- 근본 원인 파악
- 조치 방안 생성 - 분석 모드:
- combined: Trivy + Sparrow 같이 분석
- trivy-only: Trivy만 분석
취약점 리스트를 사람이 이해 가능한 보고서로 변환
STEP 4: ACTION & REPORT
분석한 결과를 Vector DB에 저장하고 지라에 티켓을 자동으로 등록합니다.
- HIGH / CRITICAL만 필터링
- Jira 티켓 자동 생성
API로 이슈 등록 (/rest/api/3/issue)
6. Agent 기반으로 설계하기
각 기능은 독립적으로 동작하도록 분리했습니다.
- Trivy 분석 Agent: 보안 결과 해석 및 요약
- Jira/Confluence Agent: 티켓 생성 / Jira / Confluence 실시간 조회
- Sparrow Agent: 코드 정적 분석 결과를 해석
이 구조를 통해 확장성과 유지 보수성을 동시에 확보할 수 있었습니다.
7. 계속 시도하며 개선하기
설계가 끝난 뒤 제가 한 일은 단 하나였습니다.
“만들어줘”
코드 작성과 구현은 대부분 AI가 수행했고 저는 방향을 설정하고 판단하는 역할에 집중했습니다.
다만, 모든 기능이 계획대로 구현된 것은 아니었습니다. 특히 Sparrow 시스템 연동에서 제약이 있었습니다. Sparrow는 Passo 업체에서 운영 중인 시스템으로 Rest API를 제공할 수 없다는 답변을 받아 예상했던 방식으로는 연동이 불가능했습니다. 이로 인해 초기 목표였던 Sparrow 데이터 기반 연동은 구현하지 못했습니다.
| 대응 방향
현재는 해당 기능을 보류한 상태이며 추후 아래와 같은 방식으로 확장할 계획입니다.
- Sparrow DB 구조 분석
- 직접 DB 접근 또는 중간 데이터 적재 방식 검토
- 필요한 데이터만 추출하여 LLM과 연동
모든 시스템이 완벽하게 연결되지 않더라도 현실적인 제약 안에서 단계적으로 확장하는 것이 더 중요했습니다
8. 프로그램 고도화하기
처음에는 모든 것이 쉬워 보였습니다. 하지만 실제 사용 단계에서는 여러 문제가 발생했습니다.
• 엉뚱한 답변
• 불안정한 결과
• 반복되는 오류
• 내장 GPU 환경에서의 성능 및 발열 한계
이때부터는 단순한 구현이 아니라 운영과 개선의 단계로 넘어갔습니다.
1) Prompt 개선
- 역할과 지침 명확화
- 출력 형식 고정
2) 컨텍스트 최적화
로컬 LLM 환경에서는 비용보다 속도와 정확도가 더 중요한 문제였습니다.
- 불필요한 정보 제거: 응답 속도 개선
- 필요한 데이터만 제공: 정확도 향상
- 입력 구조 정리: 모델 이해도 향상
3) 기록 기반 운영
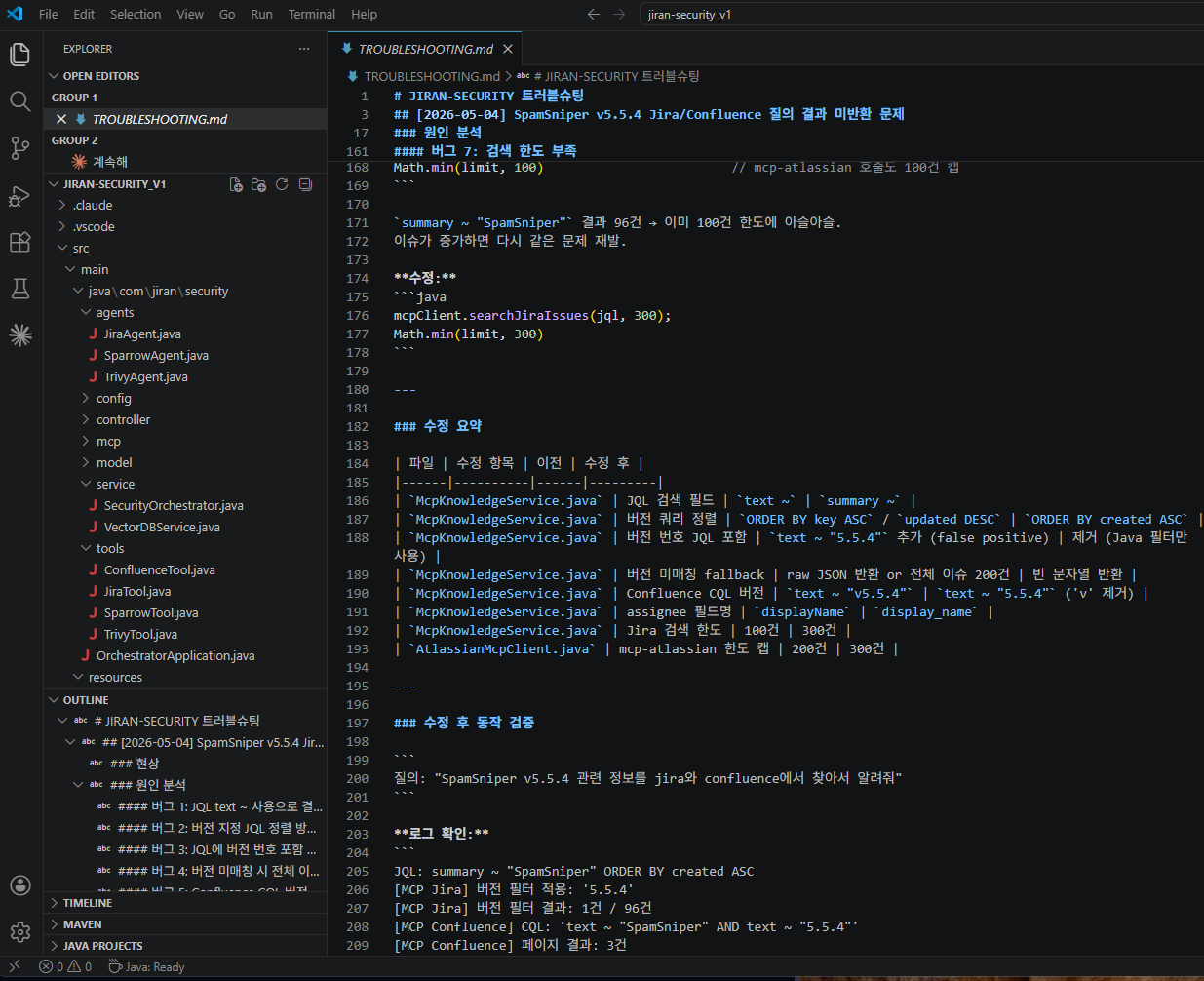
반복되는 실수를 줄이기 위해 기록 시스템을 구축했습니다.
- Troubleshooting.md: 문제 / 원인 / 해결 방법 정리
- plan.md: 작업 내역 및 TODO 관리
- 작업 로그: 모든 변경 사항 기록
4) 하드웨어 설정 최적화 (CMOS / 전력 / 발열)
로컬 LLM을 GPU 없이 CPU와 내장 GPU만으로 구동하다 보니 성능보다 발열과 안정성 문제가 더 크게 발생했습니다. 이를 해결하기 위해 BIOS(CMOS) 및 시스템 설정을 조정했습니다.
| 전력 제한 조정
- 최대 전력 사용량을 230W → 200W로 제한
- 과도한 발열을 줄이고 시스템 안정성 확보
| CPU 코어 수 조정
- 일부 코어가 아닌 20코어(전체 코어) 기준으로 운영
- 일부 코어만 사용할 경우 오히려 발열이 100도 이상 상승하는 문제 발생
| CMOS 업데이트
- 최신 BIOS로 업데이트하여 CPU 보호 기능 강화
- 전력 및 온도 제어 로직 안정화
GPU가 없는 제한적인 서버 환경에서 로컬 LLM 환경에서는 속도보다 “안정적으로 실행하는 것”이 더 중요했습니다.
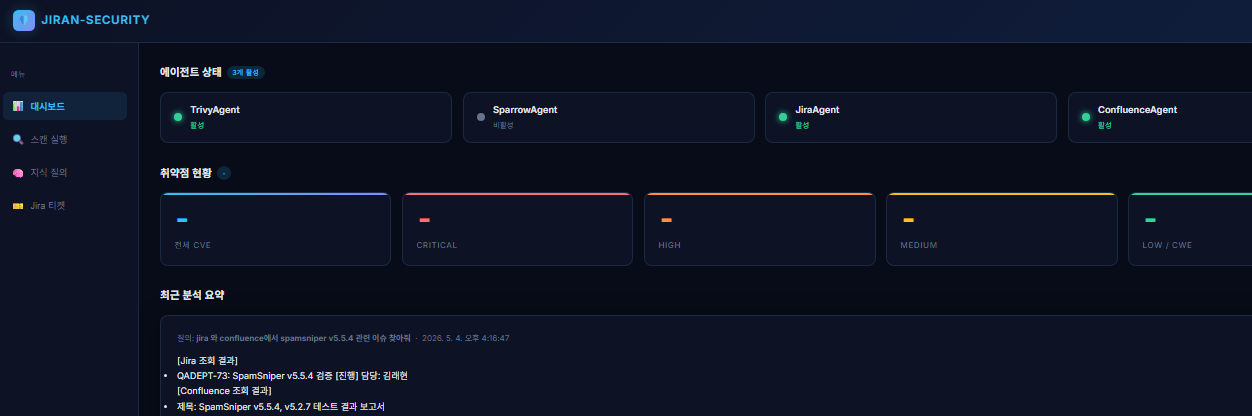
9. 구현 성과
| 보안 리포트 분석 자동화
- 기존: 수동 분석 및 보고서 작성 2~3시간
- 개선: LLM 기반 자동 분석 및 보고서 생성 → 즉시 처리 (0분 수준)
- 약 95% 이상 시간 절감
| Jira 티켓 자동 생성
- 기존: 수동 등록 및 내용 정리 약 10분
- 개선: 취약점 분석 결과 기반 자동 생성 → 약 1분 이내
- 약 90% 시간 단축
| 통합 지식 기반 분석 (RAG)
- Jira / Confluence / VectorDB 연계
- 단순 취약점 → 취약점 분석 결과에 기반한 구체적인 조치 방안 자동 생성

10. 결론: 야, 너도 할 수 있어, AI!
이 과정을 통해 얻은 결론은 명확했습니다. 중요한 것은 기술 수준이 아닙니다.
- 얼마나 명확하게 문제를 정의하는지
- 얼마나 잘 질문하는지
- 얼마나 꾸준히 개선하는지
이러한 과정 자체가 이미 업무 혁신이었습니다.
AI는 더 이상 정복의 대상이 아니라 함께 일하며 업무 효율을 높여주는 동료에 가깝습니다. 먼저 AI를 공부해야 한다는 부담에서 벗어나 작은 것부터 가볍게 시작해 본다면 누구나 자신만의 방식으로 AI를 업무에 활용할 수 있다고 생각합니다.