안녕하세요. 지란지교시큐리티 연구소에서 일하는 김련입니다.
자사 이메일 통합 보안 솔루션 스팸스나이퍼는 스팸 패턴을 수집하고 트렌드를 분석해 기업 메일 보안을 지켜왔습니다. 그러나 스팸은 차단을 우회하기 위해 새로운 패턴으로 계속 진화합니다. 문자 삽입/치환 같은 교란형 본문은 규칙 기반 대응만으로 비효율적입니다.
▶동일 문구를 반복하면서 특정 키워드만 바꾸는 패턴
삽입/치환형 예시
|
이런 패턴은 규칙을 추가할수록 예외가 증가하고, 새로운 패턴을 따라가느라 유지 보수 비용이 커집니다. 따라서 키워드의 정확한 철자 일치 대신 본문의 의미적 유사도를 기준으로 삼고, 본문을 임베딩으로 변환한 뒤 스팸 메일이 저장된 벡터 데이터베이스에서 유사한 본문을 찾아 활용하는 방안을 연구했습니다.
이 글에서는 벡터 데이터베이스 선택 이유, 주요 인덱스 유형, 그리고 성능 테스트 결과를 공유합니다.
| 벡터 데이터베이스로 Milvus를 선택한 이유
메일 데이터에는 스팸 여부를 판단할 수 있는 다양한 특징이 있지만, 이번 연구는 본문 내용만으로 탐지가 가능한지를 검증하는 데 있었습니다. 이를 위해 벡터 데이터베이스가 충족해야 할 조건은 다음과 같았습니다.
- 메일 본문이 의미적으로 유사하다면, 특정 키워드(ID, URL 등)만 달라도 유사하다고 판단할 수 있어야 합니다.
- 다국어로 이루어진 본문을 표현하고 비교할 수 있어야 합니다.
- 주어진 하드웨어 조건과 데이터 셋에 맞는 인덱스 및 파라미터 조정이 가능해야 합니다.
- 무료/오픈소스로 온프레미스(On-premise) 배포가 가능해야 합니다.
이 기준을 충족한 솔루션이 Milvus였습니다. Milvus는 FLAT, IVF_FLAT, HNSW 등 다양한 인덱스를 지원하여 정확도/속도/메모리 요구에 맞춰 최적화할 수 있고, 메타 필터 결합 검색, 확장성, SDK 지원 등 운영 친화 기능이 존재합니다. 이러한 특성 덕분에 초기 파일럿부터 향후 대규모 확장까지 무리 없이 적용할 수 있는 구조를 마련할 수 있었습니다.
| 벡터 데이터베이스 인덱스
벡터 데이터베이스에서 인덱스(Index)는 수많은 벡터 가운데 질의 벡터와 가까운 후보를 빠르게 찾기 위한 데이터 구조입니다. 인덱스가 없으면 모든 벡터를 순차적으로 비교해야 하므로 데이터가 많아질수록 검색 시간이 급격히 늘어납니다. 반대로 잘 설계된 인덱스는 검색 속도를 크게 높이면서도 정확도를 일정 수준 유지할 수 있습니다.
이 글에서는 QPS(Queries Per Second)와 정확도를 기준으로 인덱스를 비교/평가할 계획이므로, 어떤 인덱스를 사용하느냐가 결과에 직접적인 영향을 미칩니다. 따라서 테스트 대상이 되는 인덱스 유형을 이해하는 것이 중요합니다.
| Milvus의 주요 인덱스 유형
◆ FLAT
- 방식: 모든 벡터를 직접 비교하여 가장 가까운 벡터를 찾습니다.
- 특징: 구조가 단순하고 정확도가 높습니다.
- 한계: 데이터가 많아질수록 연산량이 급증해 검색 속도가 느려집니다.
- 소규모 데이터 셋이나 기준 정확도 확인용 벤치마크에 적합합니다.
◆ IVF_FLAT(Inverted File Flat)
- 방식: 전체 벡터 공간을 여러 클러스터로 분할하고, 각 벡터를 가장 가까운 Centroid에 할당합니다.
- Centroid: 클러스터를 대표하는 기준 벡터로, 해당 클러스터의 중심 역할을 합니다.
- 검색: 질의 벡터와 가까운 일부 클러스터만 탐색하여 후보를 좁힌 뒤, 그 후보 내부에서만 유사도 계산을 수행합니다.
- 한계: 데이터 분포가 불균형하면 Centroid 품질에 민감하게 반응합니다.
- IVF_FLAT의 동작 흐름은 다음과 같습니다:
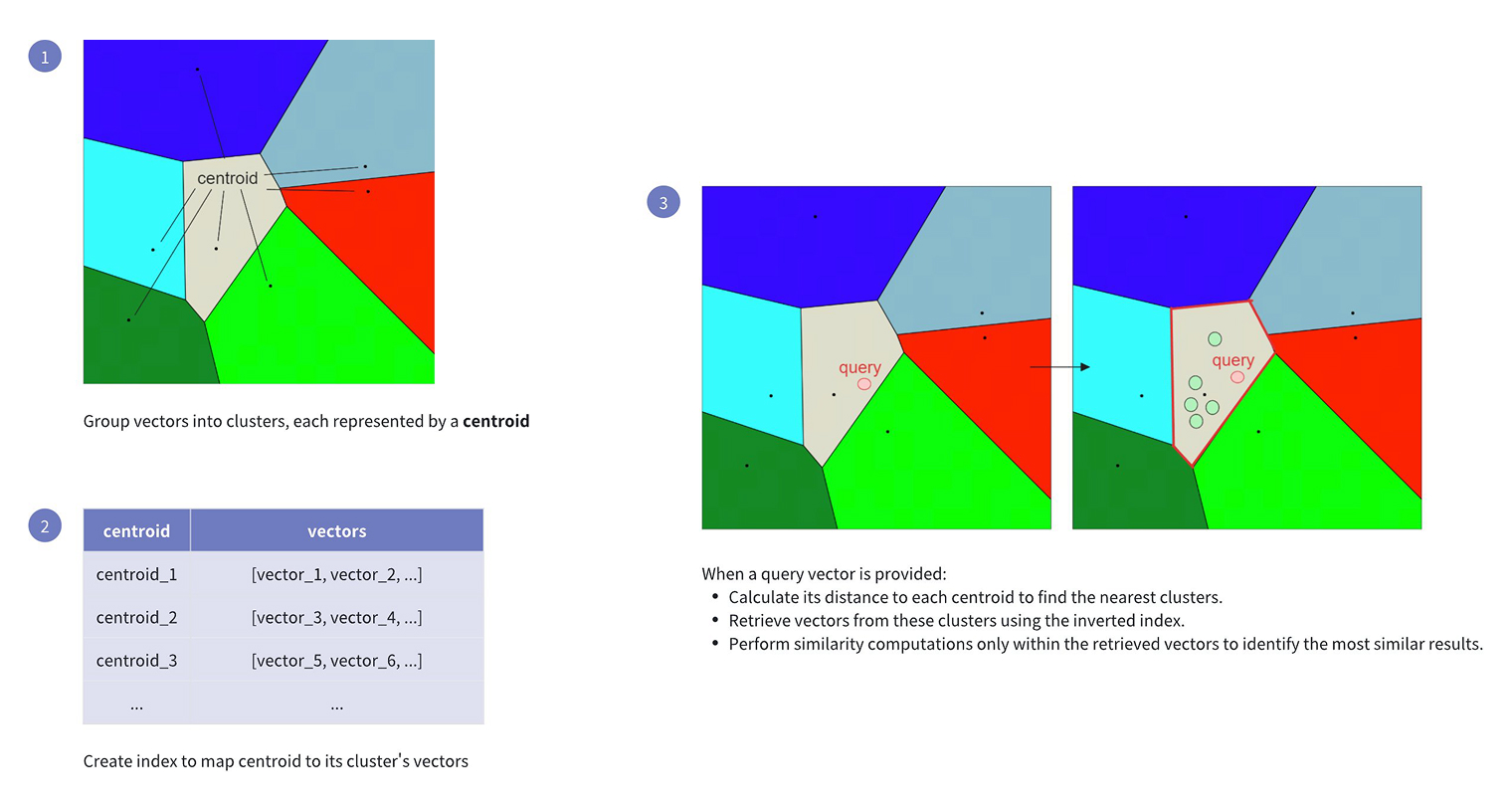
- 그룹화: 클러스터링 알고리즘으로 벡터 공간을 클러스터링하고 각 클러스터의Centroid를 생성합니다.
- 인덱스 생성: Centroid별로 벡터를 매핑해 별도의 리스트를 구성합니다.
- 검색:
- 각 Centroid와의 거리를 계산하여 가장 가까운 클러스터를 선택합니다.
- 별도의 리스트에서 후보 벡터를 수집합니다.
- 해당 후보에 대해 유사도 계산을 수행합니다.
◆ 주요 파라미터
- nlist: 생성할 클러스터 수를 지정합니다. 값이 클수록 인덱스 크기 및 메모리 사용량이 증가합니다.
- nprobe: 검색 시 고려할 클러스터 수를 지정합니다. 값이 클수록 정확도는 높아지지만 속도는 느려집니다.
◆ HNSW(Hierarchical Navigable Small World)
- 방식: 데이터 포인트(Entry point)를 계층 그래프로 연결해 근접 후보를 빠르게 찾는 인덱스입니다.
- 검색 특성: 상위 계층은 노드 수가 적고 연결 범위가 넓어 빠르게 이동할 수 있으며, 하위 계층은 밀도가 높아 정밀 탐색이 가능합니다.
- 한계: 그래프 인덱스 특성상 메모리 사용량이 큰 편이며, 파라미터 설정에 따라 성능 곡선의 변동 폭이 커 지속적 튜닝이 필요합니다.
- HNSW의 탐색 과정은 다음과 같습니다:
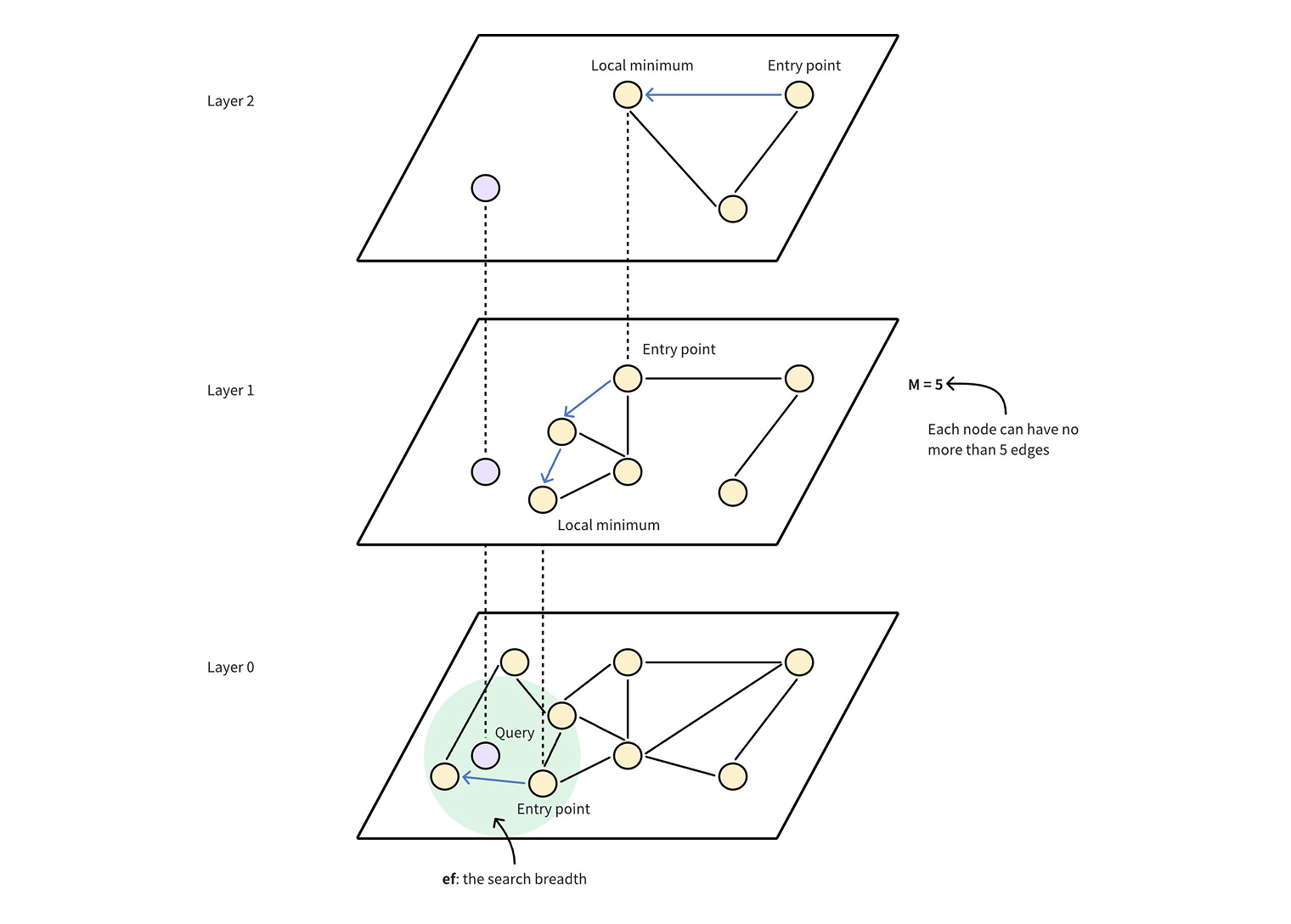
- 계층 구성: 데이터 포인트(Entry point)가 여러 계층에 걸쳐 배치되며, 높은 계층일수록 노드가 적고 연결 거리는 깁니다.
- 탐색 경로: 최상위 진입점에서 시작해 더 가까운 노드로 이동하며 계층을 내려가 대략적 위치를 확보합니다.
- 정밀 검색: 최하위 계층에서 근접 노드를 탐색해 최종 후보(top-k)를 도출합니다.
◆ 주요 파라미터
- M: 각 노드가 연결할 최대 이웃 수를 지정합니다. 값이 크면 정확도는 높아지지만 메모리 사용량이 증가합니다.
- efConstruction: 인덱스 생성 시 고려 후보 수를 지정합니다. 값이 크면 그래프의 품질은 좋아지지만 생성 시간이 늘어납니다.
- efSearch: 검색 시 후보 수를 지정합니다. 값이 크면 정확도는 높아지지만 검색 속도는 느려집니다.
| 메트릭 유형
본 실험에서는 코사인 유사도(Cosine Similarity)로 벡터 간 유사성을 측정하였습니다.
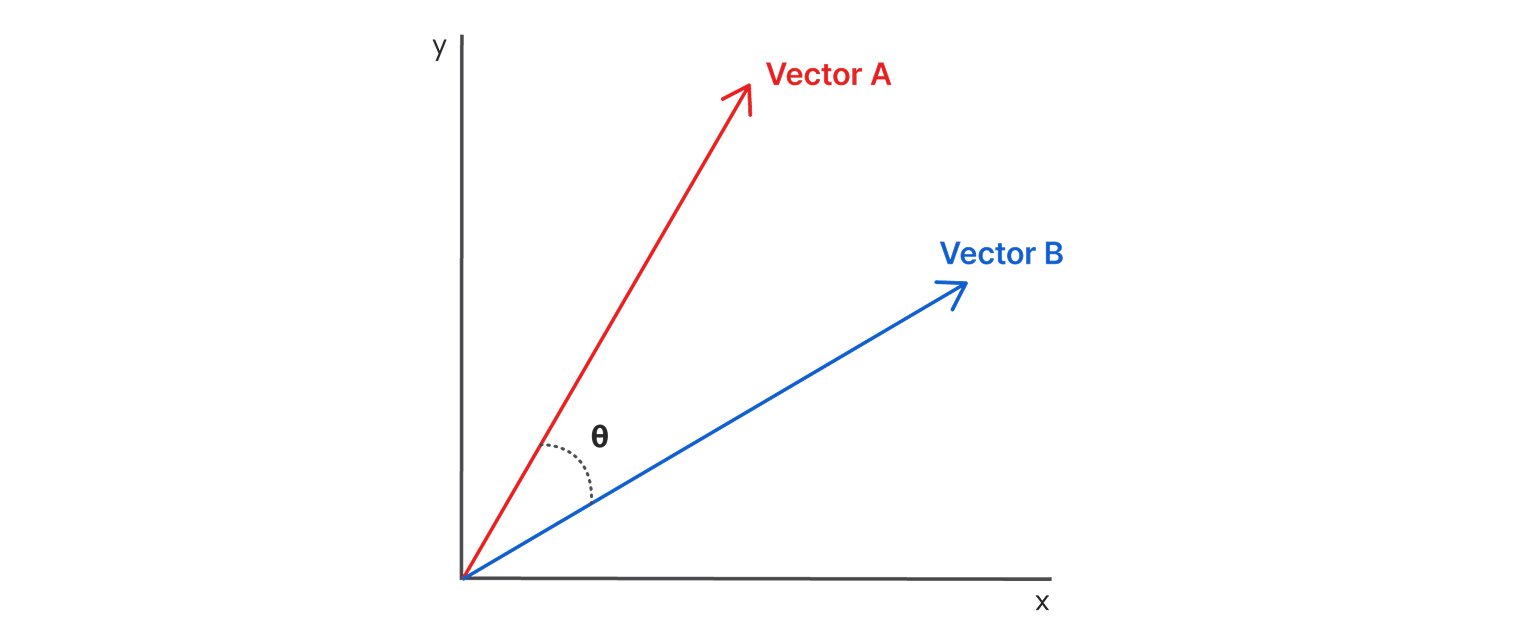
◆ 코사인 유사도(Cosine Similarity)
- 두 벡터의 방향(각도) 유사도를 측정합니다. 값이 1에 가까울수록 더 유사합니다.
- 일반적으로 범위는 [-1, 1]이며, 벡터 길이(스케일)에 둔감해 문장 길이 차이에 강건합니다.
| 인덱스 성능 테스트
이번 테스트는 운영 환경과 최대한 유사한 조건을 구축해 성능을 검증하는 것을 목표로 했습니다. 속도 지표로는 QPS(Queries Per Second)와 지연 시간(평균, p95, p99)을 사용했습니다. 반면 정확도 지표는 precision@k(P@k)와 같은 방식을 적용하기 어려웠습니다. 이는 서두에서 언급한 교란형 스팸 메일의 특성상 명확한 Ground Truth를 정의하기 어렵기 때문입니다. 대신 인덱스별 파라미터 조합에 대해 top-1 평균 유사도와 특정 임계값 이상을 만족한 결과의 비율(히트율)을 비교하는 방식으로 정확도를 평가했습니다.
◆ 용어 설명
- QPS(Queries Per Second): 초당 처리 가능한 쿼리 수
- 응답시간(Response Time): 하나의 쿼리를 처리하는데 걸리는 시간
- p95(95th Percentile): 전체 요청 중 95%가 이 시간 이내에 완료됨
- p99(99th Percentile): 전체 요청 중 99%가 이 시간 이내에 완료됨
- p95 유사도: 상위 95%에 해당하는 유사도 임계값
- 히트율(Hit Rate): 설정된 유사도 임계값을 충족하는 본문을 찾아낸 비율
- 히트율 ≥ 0.95: 유사도 0.95 이상인 검색 결과의 비율
◆ IVF_FLAT 파라미터별 속도 성능 테스트
- 최고 성능 파라미터: nlist=128, nprobe=16
nlist |
nprobe |
QPS |
평균응답시간(ms) |
p95(ms) |
p99(ms) |
16 |
16 |
17.60 |
56.81 |
75.45 |
87.85 |
32 |
16 |
21.28 |
46.99 |
66.74 |
77.76 |
64 |
16 |
25.96 |
38.52 |
57.24 |
68.67 |
128 |
16 |
27.09 |
36.92 |
55.30 |
65.91 |
128 |
32 |
25.27 |
39.58 |
57.76 |
67.79 |
128 |
64 |
23.27 |
42.98 |
62.13 |
71.36 |
128 |
128 |
20.76 |
48.18 |
65.81 |
77.05 |
◆ HNSW 파라미터별 속도 성능 테스트
- 최고 성능 파라미터: M=16, efConstruction=100, ef=32
M |
efConstruction |
ef |
QPS |
평균응답시간(ms) |
p95(ms) |
p99(ms) |
16 |
100 |
32 |
31.38 |
31.87 |
50.08 |
61.59 |
8 |
100 |
32 |
31.27 |
31.98 |
49.02 |
59.63 |
32 |
100 |
32 |
30.87 |
32.40 |
50.72 |
60.83 |
16 |
400 |
32 |
30.68 |
32.59 |
49.93 |
60.81 |
16 |
200 |
32 |
30.03 |
33.30 |
51.11 |
62.43 |
16 |
400 |
128 |
29.97 |
33.37 |
51.59 |
62.84 |
16 |
600 |
32 |
29.91 |
33.44 |
51.44 |
62.73 |
16 |
400 |
256 |
29.32 |
34.10 |
51.99 |
62.63 |
16 |
400 |
64 |
28.50 |
35.09 |
55.31 |
65.79 |
◆ IVF_FLAT과 HNSW 인덱스 속도 성능 비교
HNSW가 IVF_FLAT보다 모든 속도 지표에서 우수했습니다.
지표 |
IVF_FLAT 최고 |
HNSW 최고 |
HNSW 우위 |
QPS |
27.09 |
31.38 |
+15.8% |
응답시간 |
36.92ms |
31.87ms |
-13.7% |
p95 |
55.30ms |
50.08ms |
-9.4% |
p99 |
65.91ms |
61.59ms |
-6.6% |
◆ IVF_FLAT 파라미터별 정확도 테스트
nlist |
nprobe |
평균 유사도 |
p95유사도 |
히트율 ≥ 0.95 |
히트율 ≥ 0.97 |
32 |
16 |
0.9403 |
0.9931 |
0.339 |
0.157 |
128 |
32 |
0.9403 |
0.9931 |
0.339 |
0.157 |
128 |
16 |
0.9402 |
0.9931 |
0.339 |
0.157 |
◆ HNSW 파라미터별 정확도 테스트
M |
efConstruction |
ef |
평균 유사도 |
p95유사도 |
히트율 ≥ 0.95 |
히트율 ≥ 0.97 |
16 |
400 |
64 |
0.9403 |
0.9931 |
0.339 |
0.157 |
32 |
100 |
64 |
0.9402 |
0.9931 |
0.339 |
0.157 |
32 |
100 |
32 |
0.9401 |
0.9931 |
0.338 |
0.157 |
16 |
200 |
32 |
0.9401 |
0.9931 |
0.338 |
0.157 |
16 |
100 |
32 |
0.9399 |
0.9931 |
0.337 |
0.157 |
8 |
100 |
32 |
0.9397 |
0.9930 |
0.336 |
0.156 |
◆ 정확도 테스트 결과
IVF_FLAT과 HNSW 인덱스의 주요 파라미터를 변경하여 정확도에 어떤 차이가 있는지 확인했습니다. 그러나 결과적으로는 두 인덱스 모두에서 파라미터 변화가 검색 정확도에 미치는 영향은 미미한 수준이었습니다.
◆ 인덱스 성능 테스트 결과 요약
- 속도: 최고 성능의 HNSW 인덱스 QPS는 31.38, 평균 응답시간은 약 31ms를 기록하였습니다.
- 정확도: 본 테스트의 평가 기준에서는 두 인덱스 간 유의미한 격차를 확인하지 못했습니다. 다만 임계값(예: 유사도 ≥ 95)을 넘긴 결과의 본문을 직접 검토함으로써, 검색된 문서가 실제로 얼마나 의미적으로 유사한지 정성적으로 파악할 수 있었습니다.
| 결론
이번 실험에서는 벡터 데이터베이스 기반의 스팸 메일 본문 유사도 검색을 대상으로 성능을 측정했습니다. 키워드가 일부 교란된 경우에도 의미적 유사도를 안정적으로 포착했으며, 실무 환경에서 활용 가능한 수준의 QPS와 응답 속도를 확인했습니다. 또한 인덱스 유형과 파라미터 조합에 따라 속도 특성이 크게 달라짐을 확인했고, 데이터 셋 규모와 하드웨어 자원에 맞춘 지속적인 튜닝의 필요성을 인지했습니다.
향후에는 더 다양한 언어와 대규모 데이터셋으로 실험을 확장하고, 정량 지표(예: precision@k, recall@k)를 보강하겠습니다. 또한 온라인 환경에서의 실시간 A/B 검증을 통해 임계값 및 탐색 파라미터를 보정하여 기능적 완성도를 높여갈 계획입니다.